
type
status
date
slug
summary
tags
category
icon
password
上次编辑时间
Apr 4, 2025 02:52 PM
最近看了慕课网的Nodejs课程,跟着做了一个基于nodejs开发的网页爬虫爬了我自己的博客文章列表,感觉挺有趣的,记录一下。
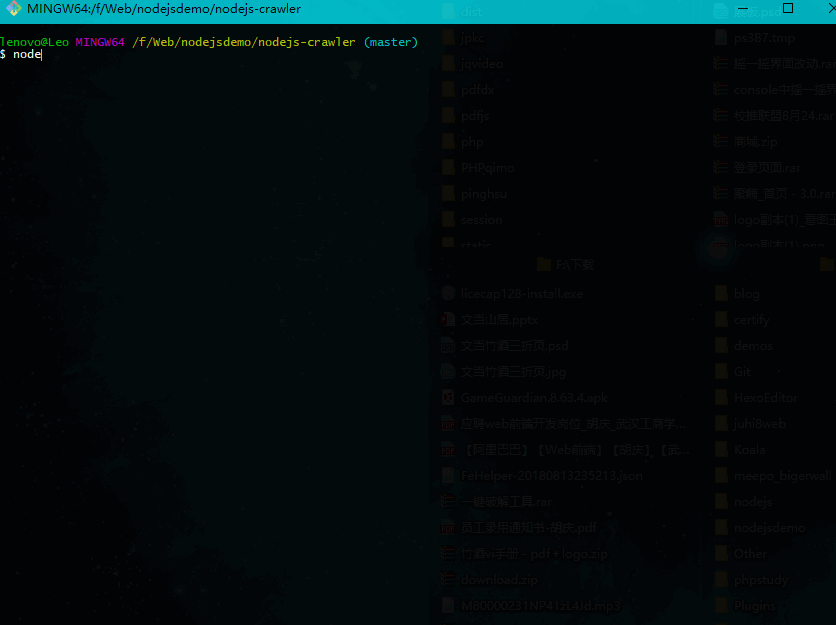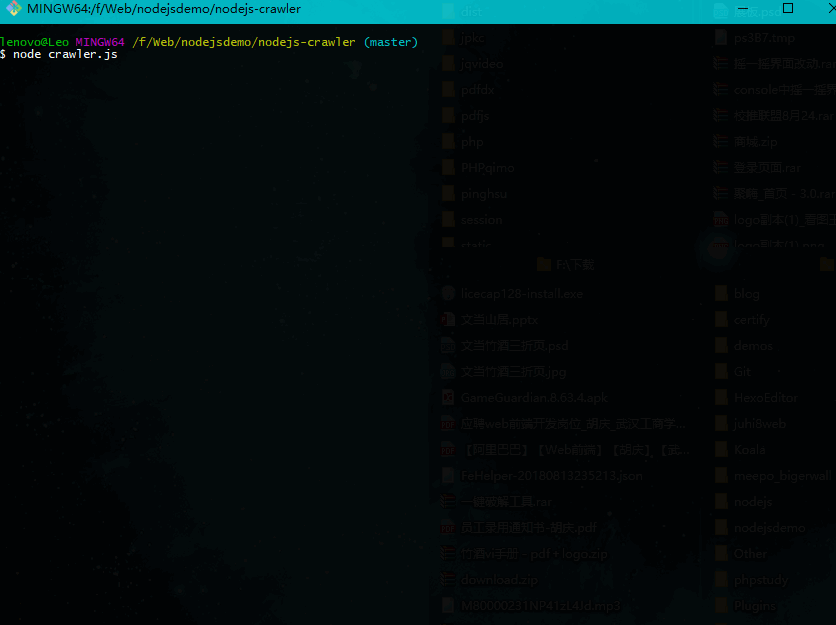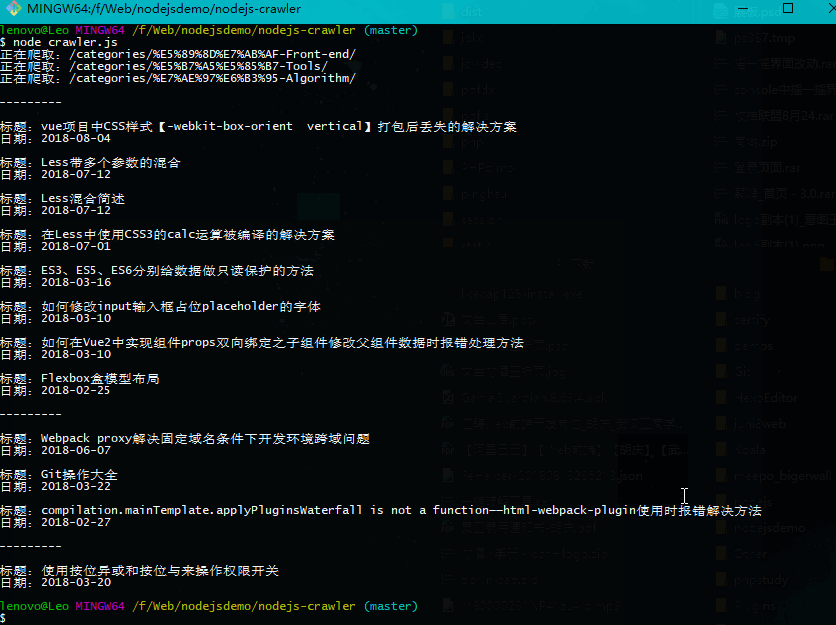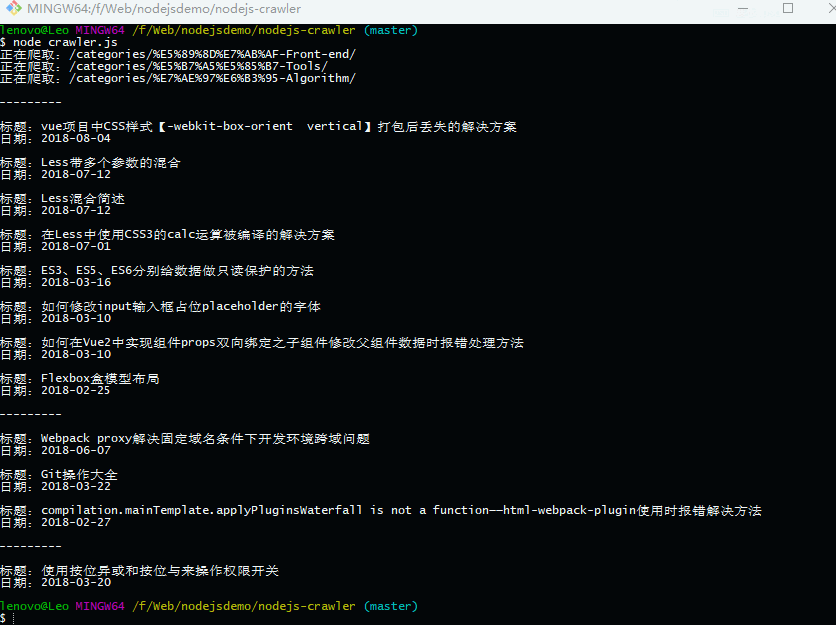
最终完成的效果如下:
主要步骤
先选择几个目录,根据目录链接,获取每个目录页面的HTML内容
处理HTML获取需要的内容
这里使用到了cheerio这个库,使用方法几乎和jQuery一样
当所有目录都遍历完成后,获取他们的resolve结果,并打印出来
总结
如果需要爬取的链接很多,可以先通过
cheerio把目录列表中的目录内容获取到,分析其链接并保存
以上就是这个nodejs爬虫小项目的结构了,完整代码可以查看我的Github仓库- 作者:Tsing
- 链接:https://www.huqing.site/full-stack/1cb94e5f-a0ad-80b5-8b97-d79b02123870
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。






